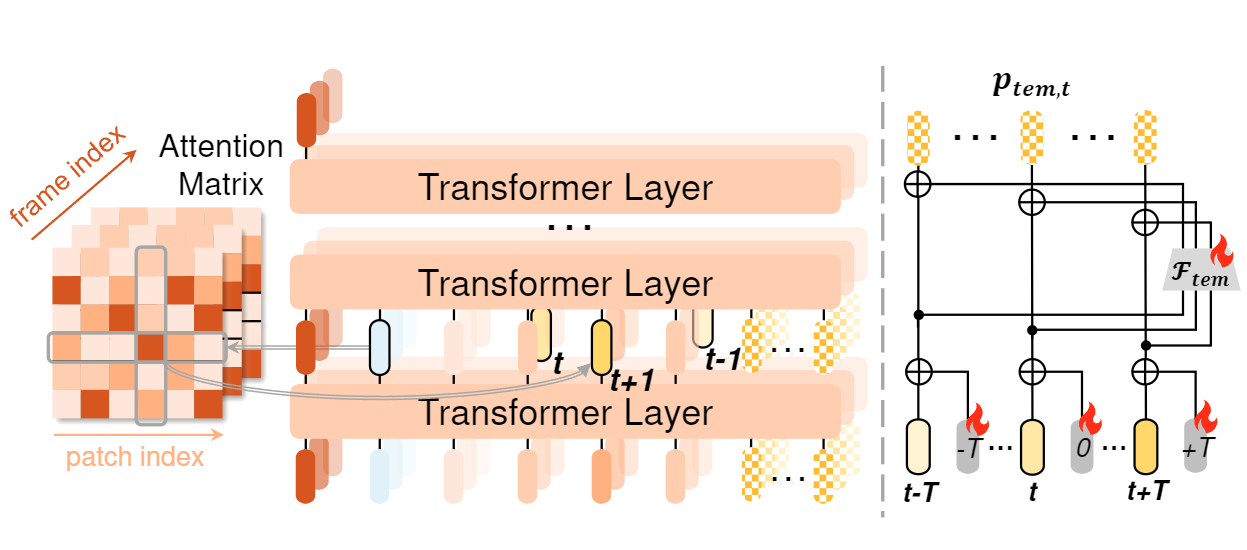
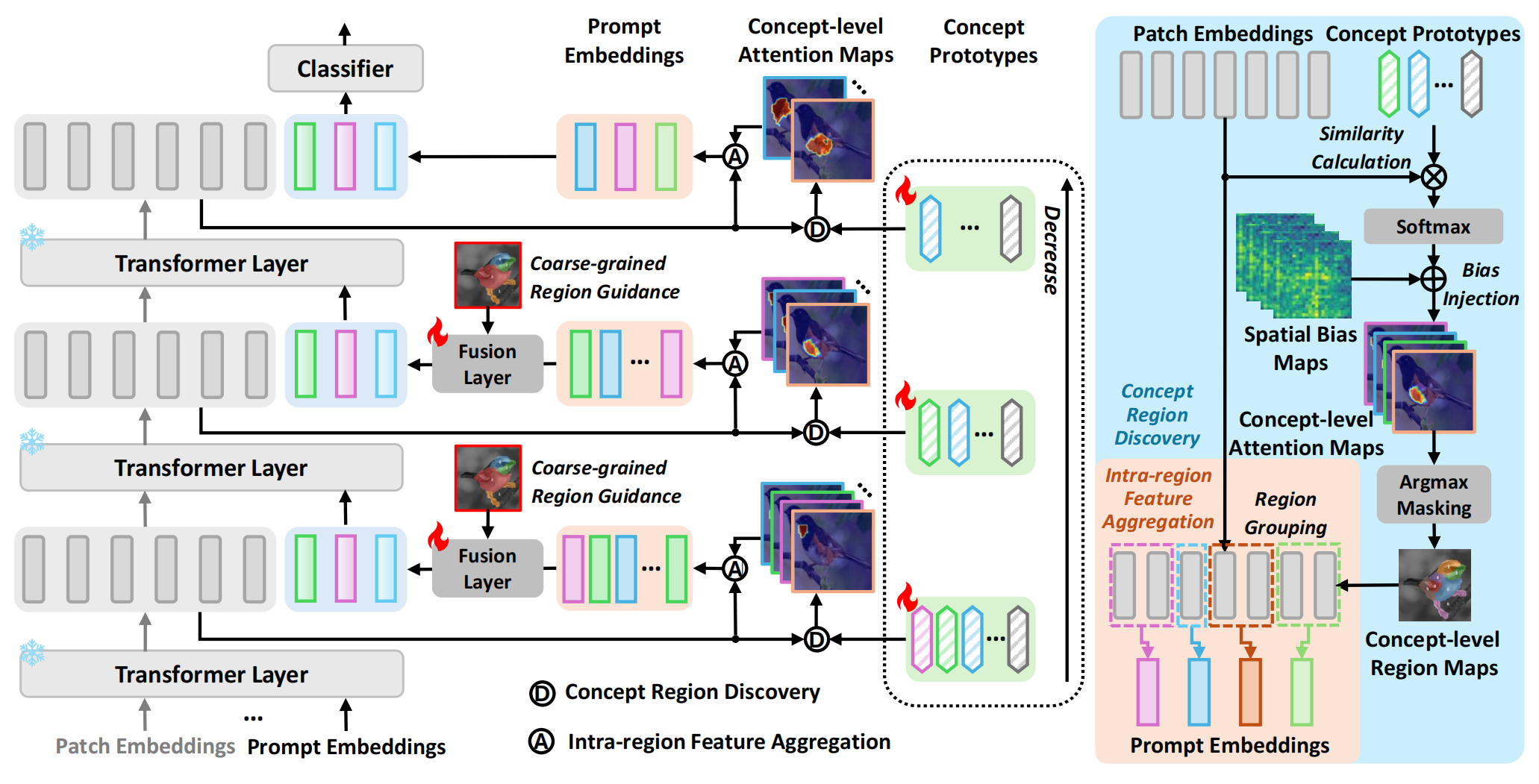
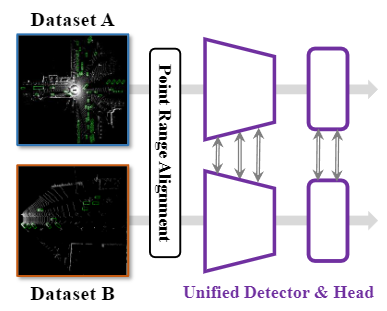
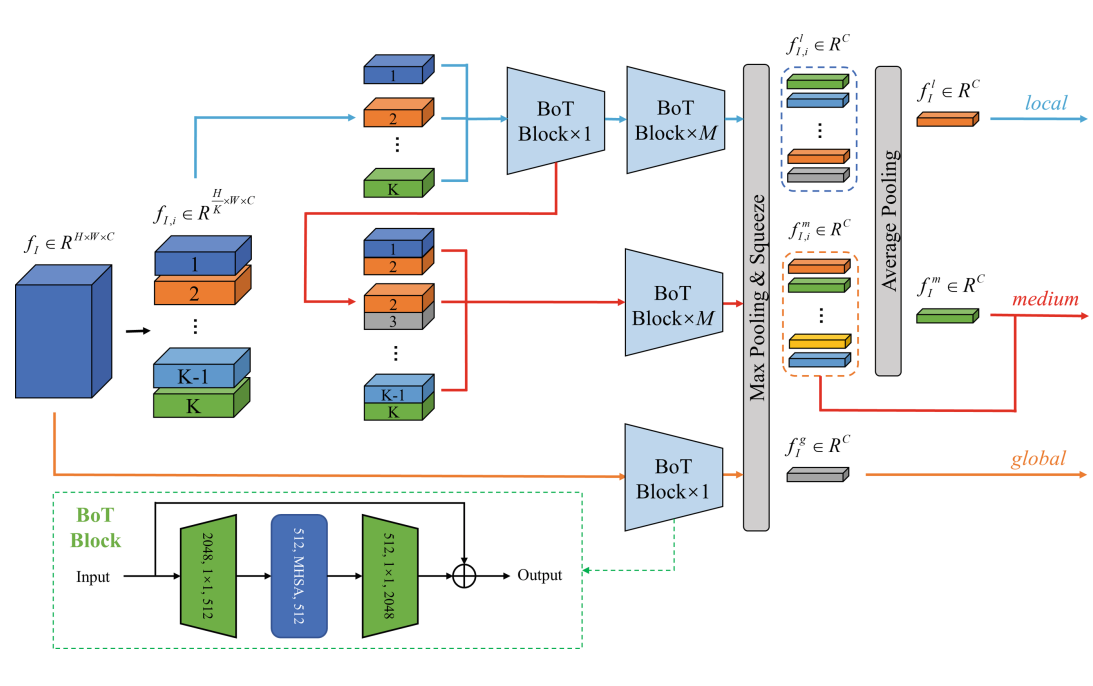
I am currently working as an algorithm engineer at OpenDataLab, Shanghai AI Lab. My main focus is on research and development for parsing chemistry-related documents. I earned my Master's degree from Tongji University in 2025, where I was advised by
Prof. Cairong Zhao. Prior to my current role, I worked as a research intern at Baidu Inc., collaborating closely with
Zhikang Zou and
Dr. Xiaoqing Ye. I also completed a research internship in the AI/ML Group at Microsoft Research Asia, Shanghai, under the supervision of
Dr. Xinyang Jiang and
Dr. Dongsheng Li. Additionally, I maintain a deep academic collaboration with
Prof. De Cheng from Xidian University. My research interests focus on computer vision and multi-modal learning, with specific work in prompt learning on VLMs, explainability and knowledge discovery in vision, text-based person re-identification, video temporal grounding, point-based 3D detection, and related areas.